Giới Thiệu Thuật Toán Di Truyền Là Gì và Ứng Dụng Thực Tế

Thuật toán di truyền (Genetic Algorithm) là một quy trình tìm kiếm giải pháp tốt nhất cho một vấn đề bằng cách sử dụng các phép toán mô phỏng các quá trình tự nhiên liên quan đến quá trình tiến hóa, chẳng hạn như sự sống sót của cá thể phù hợp nhất, trao đổi chéo nhiễm sắc thể và đột biến. Bài viết này sẽ giới thiệu "nhẹ nhàng" về cách viết các thuật toán di truyền, thảo luận một số lưu ý quan trọng khi viết thuật toán của riêng bạn và trình bày một vài ví dụ về các thuật toán di truyền đang được áp dụng hiện nay.
Thuật Toán Di Truyền: Đặt Vấn Đề
Năm nay là năm 2369 và loài người đã định cư trải dài dài khắp các vì sao. Bạn là một bác sĩ trẻ, nhiệt huyết đang làm việc tại một căn cứ trong không gian sâu thẳm luôn nhộn nhịp với những khách du lịch và thương nhân giữa các vì sao. Gần như ngay lập tức sau khi bạn đến căn cứ, một trong những người bán hàng tại nhà ga sẽ để ý đến bạn. Anh ta tự nhận mình chỉ là một thợ may đơn thuần, nhưng lại có tin đồn nói rằng anh ta là gián điệp ngầm làm việc cho một chế độ đặc biệt tồi tệ.
Hai bạn bắt đầu ăn trưa trưa cùng nhau hàng tuần và thảo luận về mọi thứ, từ chính trị đến thơ ca. Ngay cả sau vài tháng, bạn vẫn không chắc liệu anh ấy đang thực hiện những cử chỉ lãng mạn hay tìm hiểu bí mật từ bạn (mà bạn không hề có tý nào). Có lẽ là mỗi thứ một chút.
Một ngày, ngay trong bữa trưa, anh ấy đưa ra cho bạn một thử thách này: “Tôi có một lời nhắn cho anh, bác sĩ thân mến! Tất nhiên, tôi không thể nói nó là gì. Nhưng tôi sẽ cho anh biết nó dài 12 ký tự. Các ký tự đó có thể là bất kỳ chữ cái nào trong bảng chữ cái, dấu cách hoặc dấu chấm câu. Và tôi sẽ cho anh biết anh có đoán gần đúng hay không. anh rất thông minh; anh nghĩ mình sẽ tìm được lời giải chứ? "
Bạn trở lại văn phòng của mình trong khu y tế vẫn còn suy nghĩ về những gì anh ta nói. Đột nhiên, một mô phỏng trình tự gen mà bạn đã để chạy trên một máy tính gần đó như một phần của thử nghiệm cho bạn một ý tưởng. Bạn không phải là người phá mã, nhưng có thể bạn có thể tận dụng kiến thức chuyên môn của mình về di truyền học để tìm ra thông điệp của anh ấy!
Sâu Vào Lý Thuyết Một Chút
Như tôi đã đề cập ở phần đầu, thuật toán di truyền là một phương pháp tìm kiếm giải pháp bằng cách sử dụng các hoạt động mô phỏng các quá trình thúc đẩy sự tiến hóa. Qua nhiều lần lặp lại, thuật toán chọn các ứng cử viên tốt nhất (phỏng đoán) từ một tập hợp các giải pháp khả thi, kết hợp lại chúng và kiểm tra xem kết hợp nào đã đưa ta đến gần giải pháp hơn. Những ứng viên ít có lợi hơn bị loại bỏ.
Trong tình huống trên, bất kỳ ký tự nào trong thông điệp bí mật có thể là A – Z, dấu cách hoặc dấu câu cơ bản. Như vậy chúng ta có “bảng chữ cái” 32 ký tự sau để xử lý: ABCDEFGHIJKLMNOPQRSTUVWXYZ -.,!? Điều này có nghĩa là có 3212 (khoảng 1,15 × 1018) khả năng có thể xảy ra, nhưng chỉ một trong những khả năng đó là đúng. Sẽ mất quá nhiều thời gian để kiểm tra từng khả năng. Thay vào đó, một thuật toán di truyền sẽ chọn ngẫu nhiên 12 ký tự và yêu cầu thợ may/gián điệp đánh giá kết quả gần đúng với thông điệp của anh ta đến mức nào. Điều này hiệu quả hơn so với việc tìm kiếm tuần tự, ở chỗ điểm số cho phép chúng ta tinh chỉnh các ứng viên trong tương lai. Phản hồi cung cấp cho chúng ta khả năng đánh giá mức độ phù hợp của mỗi lần đoán và hy vọng tránh lãng phí thời gian vào ngõ cụt.
Giả sử chúng ta đưa ra ba lần đoán: HOMLK?WSRZDJ, BGK KA!QTPXC, và XELPOCV.XLF!. Ứng viên đầu tiên nhận được số điểm 248,2, tổ hợp thứ hai nhận được 632,5 và thứ ba nhận được 219,5. Cách tính điểm tùy thuộc vào tình huống, mà ta sẽ bàn đến sau, nhưng bây giờ hãy giả sử nó dựa trên độ lệch giữa ứng viên và thông điệp mục tiêu: điểm hoàn hảo là 0 (nghĩa là không có sai lệch nào; ứng viên và mục tiêu giống nhau), và điểm số lớn hơn có nghĩa là có độ lệch lớn hơn. Các dự đoán đạt 248,2 và 219,5 gần với thông điệp bí mật hơn so với dự đoán đạt 635,5.
Các dự đoán trong tương lai được thực hiện bằng cách kết hợp những ứng viên tốt nhất. Có nhiều cách để kết hợp các ứng viên, nhưng bây giờ chúng ta sẽ xem xét một phương pháp chéo đơn giản: mỗi ký tự trong dự đoán mới có 50–50 cơ hội được sao chép từ ứng viên mẹ đầu tiên hoặc thứ hai. Nếu chúng ta xét hai dự đoán HOMLK?WSRZDJ và XELPOCV.XLF!, ký tự đầu tiên của ứng cử viên con của chúng ta có 50% cơ hội là H và 50% cơ hội là X, ký tự thứ hai sẽ là O hoặc E, v.v.. Ứng cử viên con sẽ có thể là HELLO?W.RLD!.
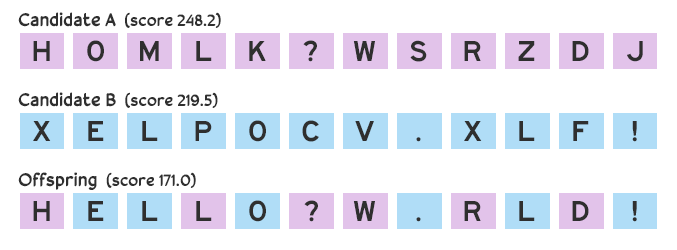
Tìm ứng viên mới thông qua lai chéo
Tuy nhiên, một vấn đề có thể nảy sinh qua nhiều lần lặp lại nếu chúng ta chỉ sử dụng các giá trị từ các ứng viên mẹ: thiếu tính đa dạng. Nếu chúng ta có một ứng cử viên bao gồm tất cả A và một ứng cử viên khác của tất cả B, thì bất kỳ con cái nào được tạo ra với chúng bằng cách lai chéo sẽ chỉ bao gồm ký tự của A và B. Chúng ta sẽ rất mệt mỏi nếu kết quả cuối cùng chứa một ký tự C nào đó.
Để giảm thiểu rủi ro này và duy trì sự đa dạng trong khi vẫn thu hẹp giải pháp, chúng ta có thể đưa ra những thay đổi nhỏ. Thay vì chia thẳng 50–50, chúng ta có thể chọn một giá trị tùy ý trong bảng lý tự thay vào chỗ này. Với đột biến này, thế hệ con cái có thể trở thành HELLO WORLD!.
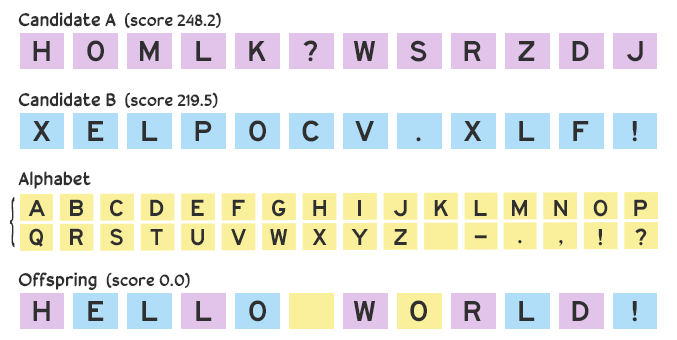
Biến dị giúp mọi thứ tươi mới hơn!
Không có gì ngạc nhiên khi các thuật toán di truyền (Genetic Algorithm) vay mượn rất nhiều từ vựng từ khoa học di truyền. Vì vậy, trước khi chúng ta đi xa hơn, hãy xem lại một số thuật ngữ:
Allele (alen): một thành viên của bảng chữ cái di truyền. Cách allele được xác định phụ thuộc vào thuật toán. Ví dụ:
0và1có thể là các allele cho một thuật toán di truyền làm việc với dữ liệu nhị phân, một thuật toán làm việc với mã có thể sử dụng con trỏ hàm, v.v. Trong kịch bản thông điệp bí mật của chúng ta, các allele là các chữ cái trong bảng chữ cái, dấu cách và các dấu câu khác nhauChromosome (nhiễm sắc thể):một chuỗi các alen xác định; một ứng viên cho giải pháp; một "lần đoán". Trong kịch bản của chúng ta,
HOMLK?WSRZDJ,XELPOCV.XLF!, vàHELLO WORLD!đều là nhiễm sắc thể.Gene: alen ở một vị trí xác định trong nhiễm sắc thể. Đối với nhiễm sắc thể
HOMLK?WSRZDJ, gen đầu tiên là H, gen thứ hai là O, gen thứ ba là M, v.v.Population (quần thể): tập hợp của một hoặc nhiều nhiễm sắc thể ứng viên được đề xuất làm giải pháp cho vấn đề.
Generation (thế hệ): quần thể trong một lần lặp lại cụ thể của thuật toán. Các ứng cử viên trong một thế hệ cung cấp gen để tạo ra quần thể của thế hệ tiếp theo.
Fitness (độ phù hợp): thước đo đánh giá mức độ gần gũi của ứng viên đối với giải pháp mong muốn. Các nhiễm sắc thể phù hợp hơn sẽ có nhiều khả năng truyền gen của chúng cho các ứng cử viên trong tương lai, trong khi các nhiễm sắc thể kém phù hợp hơn có nhiều khả năng bị loại bỏ.
Selection (chọn lọc): quá trình chọn một số ứng viên để tái sinh sản (được sử dụng để tạo ra các nhiễm sắc thể ứng viên mới) và loại bỏ những ứng viên khác. Sẽ có nhiều chiến lược chọn lọc, khác nhau ở mức độ hà khắc khi lựa chọn ứng viên yếu hơn.
Reproduction (tái sinh sản): quá trình kết hợp các gen từ một hoặc nhiều ứng viên để tạo ra ứng viên mới. Các nhiễm sắc thể của người hiến tặng được gọi là "mẹ", và các nhiễm sắc thể kết quả được gọi là "con".
Mutation (biến dị): sự đưa vào ngẫu nhiên các gen không ổn định ở thế hệ con để ngăn chặn việc mất đa dạng di truyền qua nhiều thế hệ.
Cho Tôi Xem Code Nào!
Hãy xem thử một số mã JavaScript giúp ta giải quyết vấn đề về thông điệp bí mật. Khi bạn đọc qua, hãy nghĩ xem phương pháp nào có thể được coi là “mã boilerplate” và cách triển khai của những phương pháp nào liên kết chặt chẽ hơn với vấn đề mà chúng ta đang cố gắng giải quyết:
class Candidate {
constructor(chromosome, fitness) {
this.chromosome = chromosome;
this.fitness = fitness;
}
/**
* sap xep mot array cac Candidate
* objects.
*/
static sort(candidates, asc) {
candidates.sort((a, b) => (asc)
? (a.fitness - b.fitness)
: (b.fitness - a.fitness)
);
}
}
class GeneticAlgorithm {
constructor(params) {
this.alphabet = params.alphabet;
this.target = params.target;
this.chromosomeLength = params.target.length;
this.populationSize = params.populationSize;
this.selectionSize = params.selectionSize;
this.mutationRate = params.mutationRate;
this.mutateGeneCount = params.mutateGeneCount;
this.maxGenerations = params.maxGenerations;
}
/**
* tra ket qua so nguyen ngau nhien [0-max].
*/
randomInt(max) {
return Math.floor(Math.random() * max);
}
/**
* Tao nhiem sac the moi tu alen ngau nhien.
*/
createChromosome() {
const chrom = [];
for (let i = 0; i < this.chromosomeLength; i++) {
chrom.push(this.alphabet[
this.randomInt(this.alphabet.length)
]);
}
return chrom;
}
/**
* Tao quan the voi nhiem sac the ngau nhien, va chi đinh
* moi nst voi mot diem so phu hop, chuan bi cho qua trinh tien hoa.
*/
init() {
this.generation = 0;
this.population = [];
for (let i = 0; i < this.populationSize; i++) {
const chrom = this.createChromosome();
const score = this.calcFitness(chrom);
this.population.push(new Candidate(chrom, score));
}
}
/**
* Đo lường mức độ phù hợp của nhiễm sắc thể dựa trên mức độ
* gần gũi của gen của nó đối với gen của mục tiêu;
* sử dụng sai số toàn phương trung bình.
*/
calcFitness(chrom) {
let error = 0;
for (let i = 0; i < chrom.length; i++) {
error += Math.pow(
this.target[i].charCodeAt() - chrom[i].charCodeAt(),
2
);
}
return error / chrom.length;
}
/**
* Giảm thiểu quần thể xuống chỉ với những ứng cử viên
* phù hợp nhất; gọi là chiến lược lựa chọn tinh hoa.
*/
select() {
// MSE thấp hơn thì tốt hơn
Candidate.sort(this.population, true);
this.population.splice(this.selectionSize);
}
/**
* Áp dụng trao đổi chéo và đột biến để tạo ra các nhiễm sắc
* thể con mới và làm tăng quần thể.
*/
reproduce() {
const offspring = [];
const numOffspring = this.populationSize /
this.population.length * 2;
for (let i = 0; i < this.population.length; i += 2) {
for (let j = 0; j < numOffspring; j++) {
let chrom = this.crossover(
this.population[i].chromosome,
this.population[i + 1].chromosome,
);
chrom = this.mutate(chrom);
const score = this.calcFitness(chrom);
offspring.push(new Candidate(chrom, score));
}
}
this.population = offspring;
}
/**
* Tạo nhiễm sắc thể mới thông qua trao đổi chéo đồng đều.
*/
crossover(chromA, chromB) {
const chromosome = [];
for (let i = 0; i < this.chromosomeLength; i++) {
chromosome.push(
this.randomInt(2) ? chromA[i] : chromB[i]
);
}
return chromosome;
}
/**
* (Có khả năng) đưa đột biến vào nhiễm sắc thể.
*/
mutate(chrom) {
if (this.mutationRate < this.randomInt(1000) / 1000) {
return chrom;
}
for (let i = 0; i < this.mutateGeneCount; i++) {
chrom[this.randomInt(this.chromosomeLength)] =
this.alphabet[
this.randomInt(this.alphabet.length)
];
}
return chrom;
}
/**
* Trả kết quả liệu trình thực thi sẽ tiếp tục xử lý
* thế hệ tiếp theo hay nên dừng lại.
*/
stop() {
if (this.generation > this.maxGenerations) {
return true;
}
for (let i = 0; i < this.population.length; i++) {
if (this.population[i].fitness == 0) {
return true;
}
}
return false;
}
/**
* Thực hiện lặp đi lặp lại các thao tác di truyền
* trên tập hợp nhiễm sắc thể ứng viên nhằm
* cố gắng tìm được giải pháp phù hợp nhất.
*/
evolve() {
this.init();
do {
this.generation++;
this.select();
this.reproduce();
} while (!this.stop());
return {
generation: this.generation,
population: this.population
};
}
}
const result = new GeneticAlgorithm({
alphabet: Array.from('ABCDEFGHIJKLMNOPQRSTUVWXYZ !'),
target: Array.from('HELLO WORLD!'),
populationSize: 100,
selectionSize: 40,
mutationRate: 0.03,
mutateGeneCount: 2,
maxGenerations: 1000000
}).evolve();
console.log('Generation', result.generation);
Candidate.sort(result.population, true);
console.log('Fittest candidate', result.population[0]);
Chúng ta bắt đầu bằng cách xác định object data Candidate đơn thuần để ghép các nhiễm sắc thể với điểm phù hợp của chúng. Ngoài ra còn có một method sắp xếp tĩnh được kèm theo để tiện sử dụng; method rất hữu ích khi chúng ta cần tìm hoặc xuất ra các nhiễm sắc thể phù hợp nhất.
Tiếp theo, chúng ta có một class GeneticAlgorithm tự thực hiện thuật toán di truyền.
Hàm tạo (constructor) tiếp nhận object gồm các tham số khác nhau cần thiết cho mô phỏng. Hàm này cho ta cách chỉ định bảng chữ cái di truyền, thông điệp đích và các tham số khác phục vụ cho việc xác định các ràng buộc mà theo đó mô phỏng sẽ chạy. Trong ví dụ trên, chúng ta dự đoán mỗi thế hệ có tiệp nhiễm sắc thể gồm 100 ứng cử viên. Từ đó, chỉ có 40 nhiễm sắc thể sẽ được chọn để tái sinh sản. Chúng ta có 3% cơ hội tạo ra đột biến với tối đa hai gen khi đột biết xảy ra. Giá trị maxGenerations đóng vai trò như một biện pháp bảo vệ; nếu không tìm được giải pháp sau một triệu thế hệ, chúng ta sẽ ngưng chạy script.
Một điểm đáng nói là quần thể, kích thước chọn lọc và số thế hệ tối đa được cung cấp khi chạy thuật toán là khá nhỏ. Các vấn đề phức tạp hơn có thể yêu cầu không gian tìm kiếm lớn hơn, do đó làm tăng mức sử dụng bộ nhớ của thuật toán và thời gian chạy. Tuy nhiên, việc sử dụng thông số đột biến nhỏ rất quan trọng. Nếu đột biến quá lớn, chúng ta sẽ mất bất kỳ lợi ích nào của việc tái sinh sản các ứng viên dựa trên "điểm phù hợp" và mô phỏng bắt đầu trở thành một cuộc tìm kiếm ngẫu nhiên.
Các phương thức như randomInt(), init(), và run() có thể được coi là "boilerplate" (mã lặp), nhưng không có nghĩa là các method này không mang lại ý nghĩa gì cho mô phỏng. Ví dụ, các thuật toán di truyền sử dụng nhiều tính ngẫu nhiên. Mặc dù hàm Math.random() tích hợp sẵn đã phù hợp với mục đích của chúng ta, ta vẫn cần một trình tạo ngẫu nhiên chính xác hơn cho các vấn đề khác.Crypto.getRandomValues() cung cấp nhiều giá trị ngẫu nhiên mạnh về mặt mã hóa hơn.
Hiệu suất cũng là một điều cần cân nhắc. Và hãy nhớ rằng, các thao tác sẽ được lặp đi lặp lại nhiều lần. Bạn có thể cần phải micro-optimize code trong các vòng lặp, sử dụng cấu trúc dữ liệu tiết kiệm bộ nhớ hơn và dùng inline code hơn là tách nó thành các hàm/phương thức; bất kể ngôn ngữ triển khai của bạn là gì.
Việc triển khai các phương thức như calcFitness(), select(), reproduce(), và thậm chí là stop() cụ thể cho vấn đề mà chúng ta đang cố gắng giải quyết.
calcFitness() trả về giá trị ước lượng mức độ phù hợp của nhiễm sắc thể so với một số tiêu chí mong muốn - trong trường hợp của chúng ta, mức độ gần khớp với thông điệp bí mật. Tính toán độ phù hợp hầu như luôn phụ thuộc vào tình huống; đoạn mã của chúng ta tính toán Sai số toàn phương trung bình bằng cách sử dụng các giá trị ASCII của mỗi gen, nhưng các số liệu khác có thể phù hợp hơn. Ví dụ, ta có thể tính toán khoảng cách Hamming hoặc Levenshtein giữa hai giá trị hoặc thậm chí kết hợp nhiều phép đo. Cuối cùng, điều quan trọng đối với hàm tính toán độ phù hợp là trả về một phép đo hữu ích liên quan đến vấn đề đang xảy ra, chứ không chỉ đơn giản là boolean “is-fit” / “isn't fit”.
Phương thức select() thể hiện chiến lược chọn lọc tinh hoa - chỉ chọn những ứng cử viên phù hợp nhất trong toàn bộ quần thể để tái sinh sản. Như đã đề cập trước đó, ta có thể dùng chiếc lược khác, chẳng hạn như chọn lọc cạnh tranh, chọn các ứng cử viên phù hợp nhất từ nhóm ứng viên riêng lẻ trong quần thể và chọn lọc Boltzmann, dùng áp lực tăng dần để chọn ứng viên. Mục đích của các cách tiếp cận khác nhau này là để đảm bảo nhiễm sắc thể có cơ hội truyền lại các gen có thể được chứng minh là có lợi sau này, mặc dù nó có thể không rõ ràng ngay lập tức. Bạn có thể dễ dàng tìm thấy mô tả chuyên sâu về những chiến lược này và các chiến lược chọn lọc khác, cũng như ví dụ triển khai cụ thể tương ứng.

Ta có nhiều chiến lược chọn lọc khác nhau
Cũng có nhiều cách thức kết hợp các gen. Code của chúng ta tạo ra đời con bằng cách sử dụng trao đổi chéo đồng nhất trong đó mỗi gen có cùng khả năng được chọn từ một trong các gen. Các chiến lược khác có thể ưu tiên gen mẹ này hơn gen mẹ khác. Một chiến lược phổ biến khác là trao đổi chéo tại điểm k, trong đó các nhiễm sắc thể được phân chia tại điểm k dẫn đến các lát cắt được kết hợp để tạo ra đời con. Các điểm giao nhau có thể là cố định hoặc lựa chọn ngẫu nhiên.
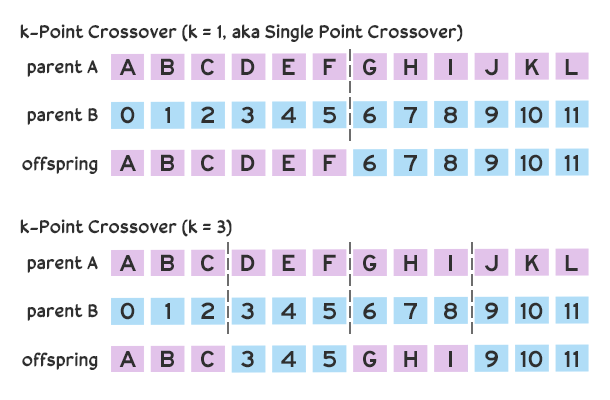
Mô tả chiến lược trao đổi chéo tại điểm k
Chúng ta cũng không bị giới hạn chỉ với hai nhiễm sắc thể mẹ; chúng ta có thể kết hợp các gen từ ba ứng cử viên trở lên hoặc thậm chí chỉ từ một ứng cử viên duy nhất. Hãy tưởng tượng ta có một thuật toán để phát triển một hình ảnh bằng cách vẽ các đa giác ngẫu nhiên. Trong trường hợp này, các nhiễm sắc thể của chúng ta được thực hiện dưới dạng dữ liệu hình ảnh. Trong mỗi thế hệ, hình ảnh phù hợp nhất được chọn từ quần thể và đóng vai trò là hình ảnh mẹ, và tất cả các ứng cử viên con được tạo ra bằng cách vẽ các đa giác của chính chúng vào một bản sao của hình ảnh cha mẹ. Nhiễm sắc thể / hình ảnh mẹ đóng vai trò là cơ sở và nhiễm sắc thể / hình ảnh con cái là những đột biến / hình vẽ độc nhất trên hình ảnh mẹ.
Genetic Algorithm - Thuật toán di truyền trong thực tế
Các thuật toán di truyền có thể được dùng cho vui và kiếm lợi nhuận. Có lẽ hai trong số những ví dụ phổ biến nhất về thuật toán di truyền đang được áp dụng hiện nay là BoxCar 2D và ăng-ten băng tần X phát triển của NASA.
BoxCar 2D là một mô phỏng sử dụng các thuật toán di truyền để phát triển “chiếc xe” tốt nhất có khả năng vượt qua các địa hình mô phỏng. Chiếc xe được xây dựng từ tám vectơ ngẫu nhiên tạo ra một đa giác, thanh gắn và bánh xe đến các điểm ngẫu nhiên. Trang web của dự án có thể được tìm thấy tại boxcar2d.com, tại đây bạn có thể xem bản tóm tắt ngắn gọn về thuật toán trong trang giới thiệu và một bảng thành tích giới thiệu một số thiết kế tốt. Buồn một cái là, trang web sử dụng Flash, khiến nhiều người không thể tiếp cận được - trong trường hợp đó, bạn có thể tìm thấy nhiều bản ghi màn hình khác nhau trên YouTube nếu tò mò. Bạn cũng có thể muốn xem một mô phỏng tương tự (tuyệt vời) do Rafael Matsunaga viết bằng công nghệ HTML5 có sẵn tại rednuht.org/genetic_cars_2.
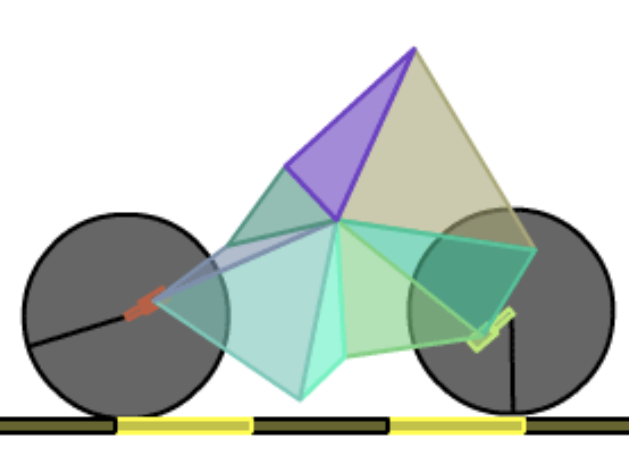
Một chiếc xe hơi được phát triển trong BoxCar 2D, hình ảnh từ bảng xếp hạng BoxCar 2D
Năm 2006, sứ mệnh Space Technology 5 của NASA đã thử nghiệm nhiều công nghệ mới khác nhau trong không gian. Một trong những công nghệ như vậy là các ăng-ten mới được thiết kế bằng cách sử dụng thuật toán di truyền. Thiết kế một ăng-ten mới có thể là một quá trình rất tốn kém và mất thời gian. Nó đòi hỏi kiến thức chuyên môn đặc biệt và thất bại thường xuyên xảy ra khi các yêu cầu thay đổi hoặc nguyên mẫu không hoạt động như mong đợi. Các ăng-ten cải tiến được tạo ra trong khoảng thời gian ngắn hơn, hoạt động hiệu quả hơn và sử dụng ít năng lượng hơn. Toàn bộ nội dung của bài báo thảo luận về quá trình thiết kế được cung cấp miễn phí trên mạng (Thiết kế Ăng-ten Tự động với Thuật toán Tiến hóa). Các thuật toán di truyền cũng đã được sử dụng để tối ưu hóa các thiết kế ăng-ten hiện có nhằm mang lại hiệu suất cao hơn.

Ăng-ten cải tiến tốt nhất cho loại yêu cầu của chúng, hình ảnh lấy từ bài báo Thiết kế ăng-ten tự động
Thuật toán di truyền thậm chí đã được sử dụng trong thiết kế web! Một dự án cấp cao của Elijah Mensch (Tối ưu hóa thiết kế trang web thông qua thuật toán di truyền tương tác) đã sử dụng chúng để tối ưu hóa giao diện carousel thông qua CSS và cách tính điểm phù hợp với A / B testing.
Bố cục đẹp nhất từ thế hệ 1 và 9, hình ảnh lấy từ bài báo Tối ưu hóa thiết kế trang web
Lời kết
Bây giờ, bạn đã có hiểu biết cơ bản về thuật toán di truyền (Genetic Algorithm) là gì và đủ quen thuộc với vốn từ vựng của chúng để giải mã bất kỳ tài nguyên nào bạn có thể bắt gặp trong nghiên cứu của riêng mình. Nhưng hiểu lý thuyết và thuật ngữ chỉ là một nửa chặng đường. Nếu bạn định viết thuật toán di truyền của riêng mình, bạn cũng phải hiểu vấn đề cụ thể của bản thân. Dưới đây là một số câu hỏi quan trọng cần tự hỏi bản thân trước khi bắt đầu:
Làm thế nào tôi có thể trình bày vấn đề của mình dưới dạng nhiễm sắc thể? Alen nào sẽ phù hợp cho vấn đề?
Tôi có biết mục tiêu là gì không? Đó là, những gì tôi đang tìm kiếm? Đó có phải là một giá trị cụ thể hoặc bất kỳ giải pháp nào có độ phù hợp vượt quá một ngưỡng nhất định không?
Làm cách nào tôi có thể xác định độ phù hợp của các ứng viên của mình?
Làm cách nào để tôi có thể kết hợp và thay đổi các ứng viên để tạo ra các ứng viên mới cho giải pháp?
Bài viết hy vọng đã giúp bạn hiểu thêm và yêu hơn cách các chương trình máy tính lấy cảm hứng từ thiên nhiên - không chỉ về hình thức, mà còn về quy trình và chức năng. Hãy chia sẻ bài viết nếu thấy hay nhé.
Theo dõi chúng tôi trên Facebook.
Theo Sitepoint.



Nhận xét
Đăng nhận xét